Decision Tree Machine Learning
Not only you can make a robust rational decision using the SpiceLogic Decision Tree Software, but also you can discover how others made the decision by mining data. Yes, learning from data and making a Decision Tree from that learning is called Decision Tree Machine Learning. While 'Normative Decision Theories' is all about how to make a rational decision for a rational agent, 'Descriptive Decision Theories' is about how people make a decision, not necessarily whether the decisions are Rational or Not. It is like, learning to read others' minds, based on their activity.
The SpiceLogic Decision Tree software can serve you to apply both normative and description decision theories. Using machine learning, the decision tree software can analyze data and create both a Classification Decision Tree and a Regression Tree.
Classification Decision Tree
Classification tree analysis is a kind of analysis where the predicted outcome is a Category (or class) to which the data belongs. Say you want to sell hot dogs near a Tennis Court where Tennis Players are the primary customers. But you figured that not every day the players show up. You gathered some data like Outlook of the day, Temperature, Wind, Humidity, etc, and tried to figure out what makes them decide to come out and play Tennis. Say, your data looks like this:
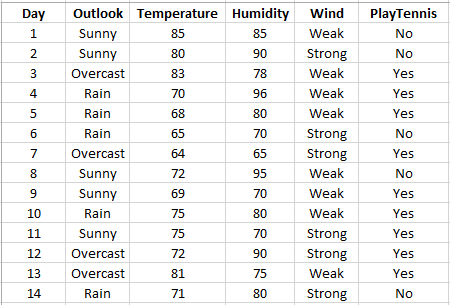
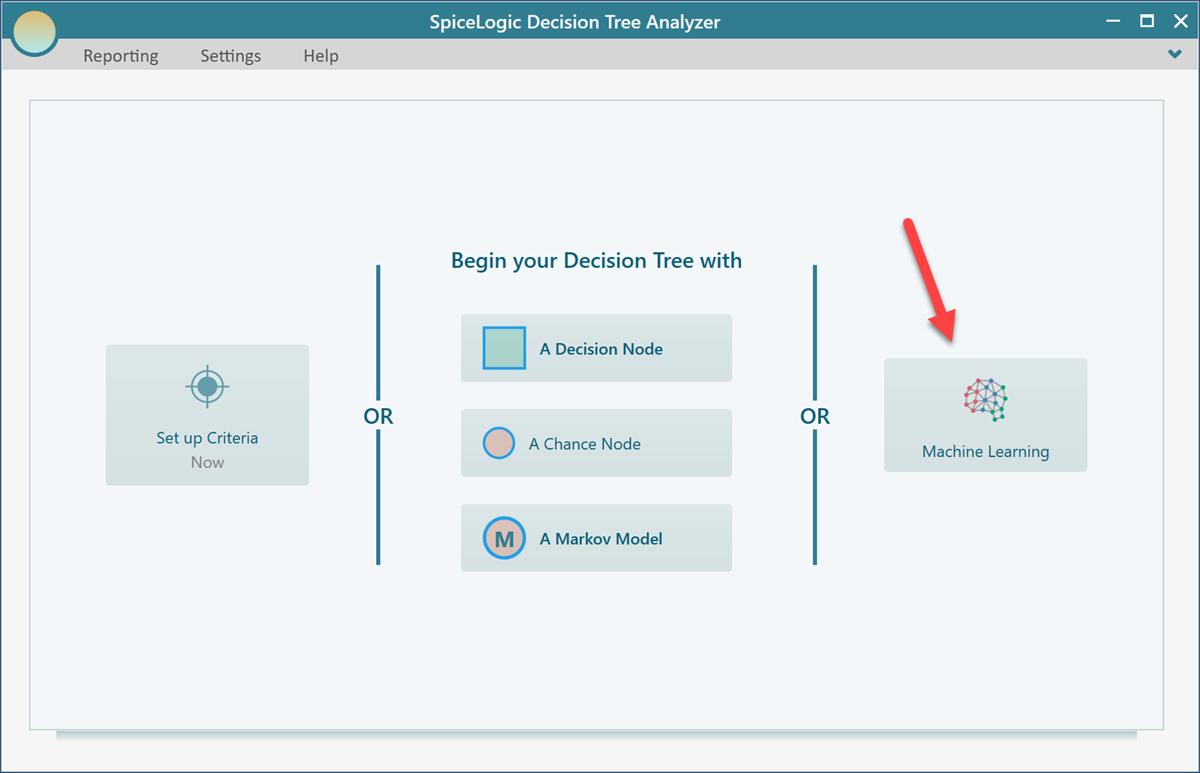
At this moment, SpiceLogic Decision Tree Software can analyze data from CSV files, Excel files, and SQL Server databases. Say, you have an Excel file that contains this data. In order to discover a decision tree from this data set, start the Decision Tree software and click the Machine Learning button as shown below.
Then select the data source type. Let's choose the Excel data source.
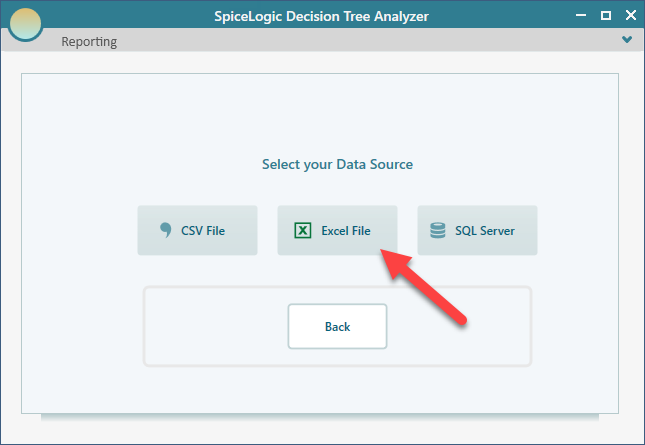
Then select the Excel file and select the Sheet that contains your data.
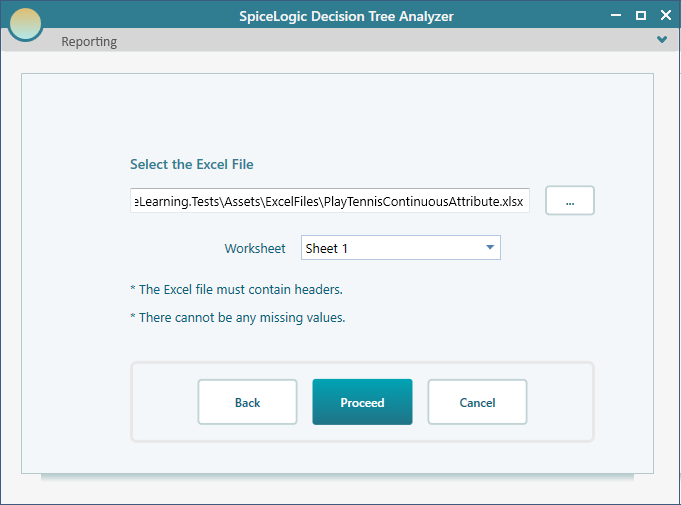
After clicking Proceed, you will see the list of all columns from that data set. Select the columns that you think are important in the decision. Obviously, the Day Number has nothing to do with the decisions, so Uncheck the "Day" column. Then select "PlayTennis" as the Decision Column.
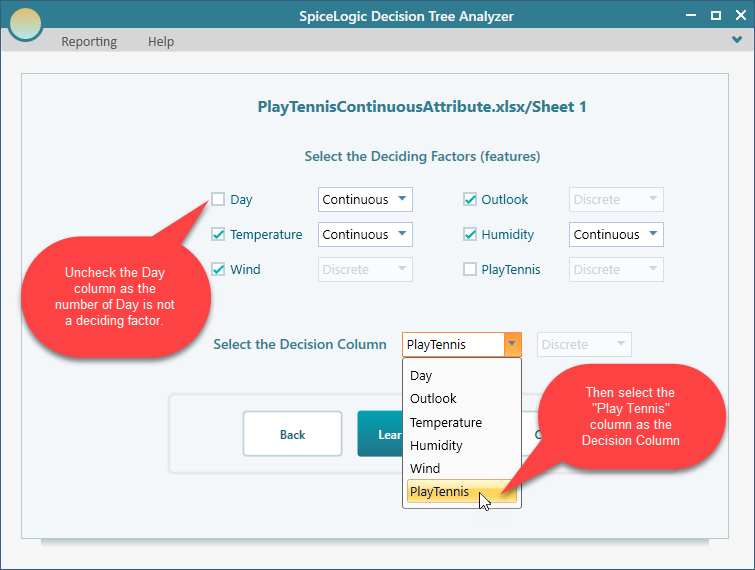
Then click the button "Learn from Data"
Once the Learn from Data button is clicked, applying a Machine Learning Algorithm, a Decision Tree will be generated as shown below.
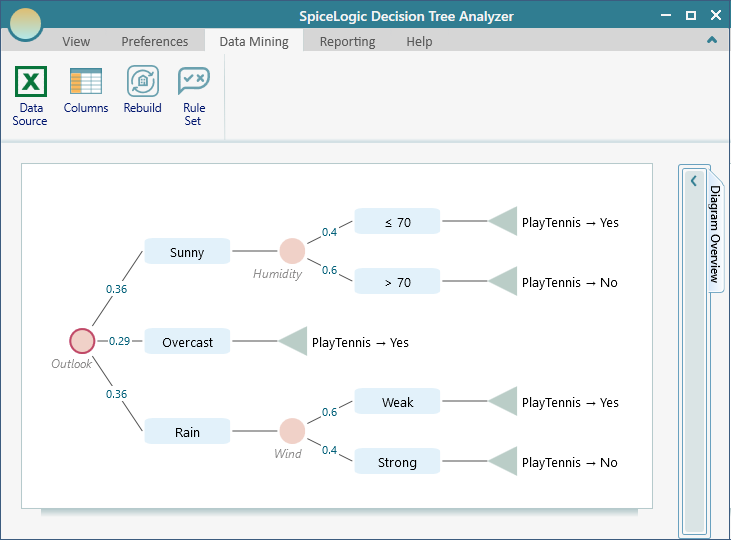
Click the Rule Set button to view the Generated Rule Set.
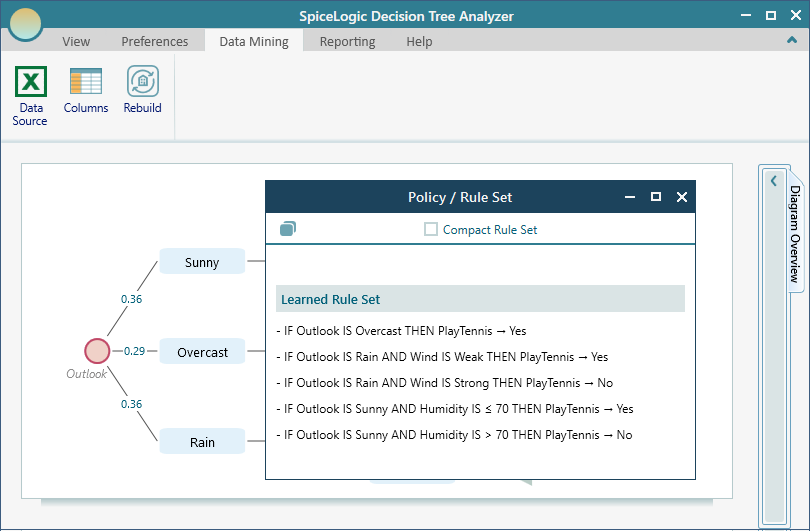
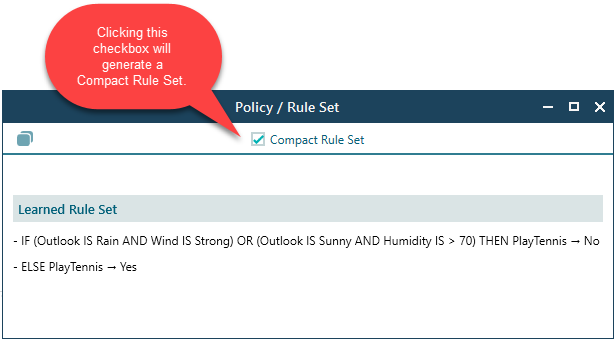
A compact rule set can be generated by clicking the Compact checkbox. Notice that the compact rule set combines the conditions using "OR".
Click the "Rebuild" button to rebuild the tree again from the same data source. Click the "Columns" button to change the columns that you want to consider as deciding factors. Click the Data Source button to change the data source like SQL Server database, Excel / CSV file path, etc.

Test against a data source and get the Confusion Matrix
For a classification tree, once the decision tree is created after machine learning, you can test the tree against a data source to get a Confusion Matrix and other performance metrics. Click the "Test" button as shown here.
Once you click that button, you will be prompted to select a data source. Select a data source the same as you did for the first time when you generated the tree. Then you will get a Confusion Matrix view like this:
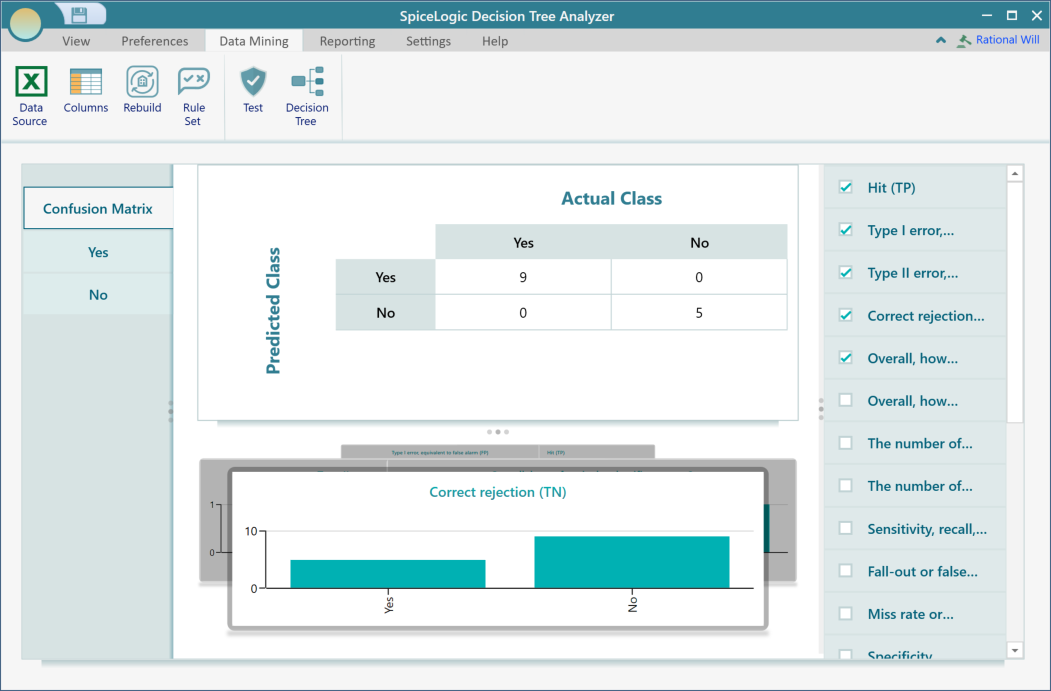
You can see more details about each class performance by clicking a class result from the left menu. For example, clicking the "Yes" menu button shows this view.
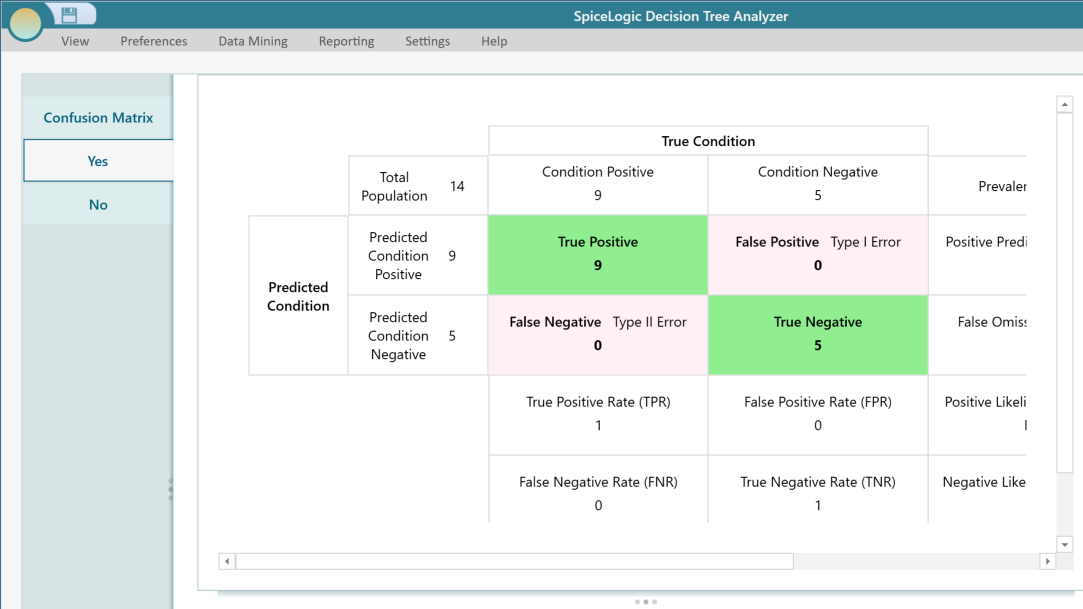
You can learn about all of these metrics from the Wikipedia Confusion matrix page.
Regression Tree
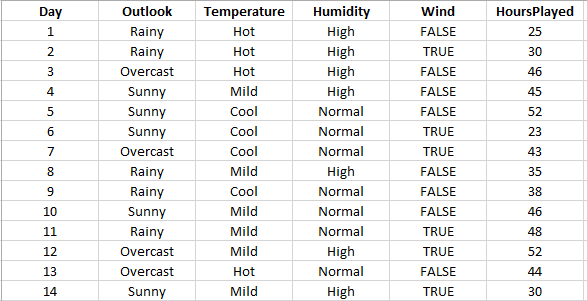
Regression Tree analysis is a kind of analysis where the predicted outcome is a real number like "price of a house", "expected salary" etc. In order to perform a Regression tree analysis, the procedure is the same as the Classification Decision Tree analysis, except the Decision Column, needs to be a Continuous (number type) variable. Say, you want to understand, how long a Tennis player plays tennis in a day based on various factors like Outlook, Temperature, Wind, Humidity, etc. Say, your data set looks like this:
Following the same procedure, as shown for Classification Tree Analysis, you can generate the Tree and the generated tree will look like this.
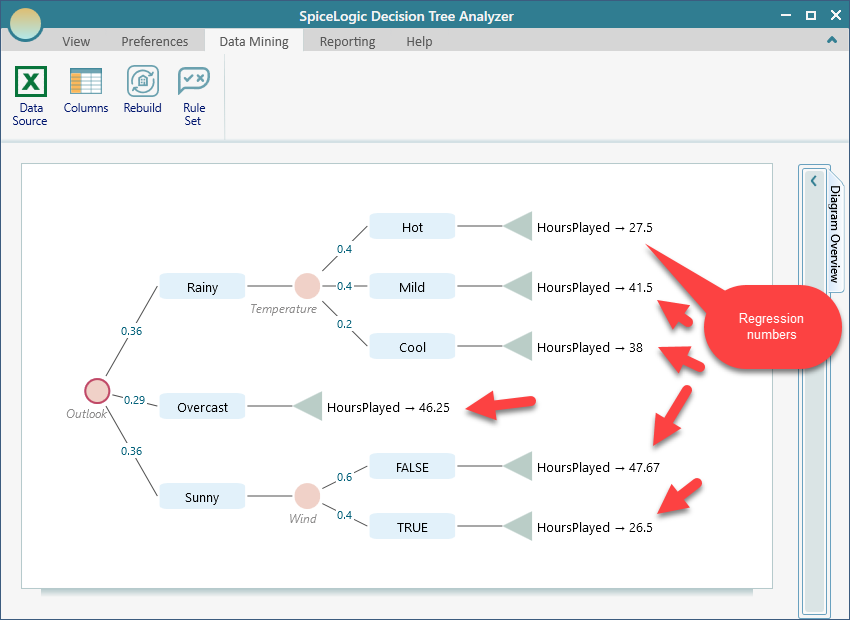
Please note that the "Test" button for testing against a data source won't be visible if it is a regression tree. Because a confusion matrix will make sense for a classification tree,
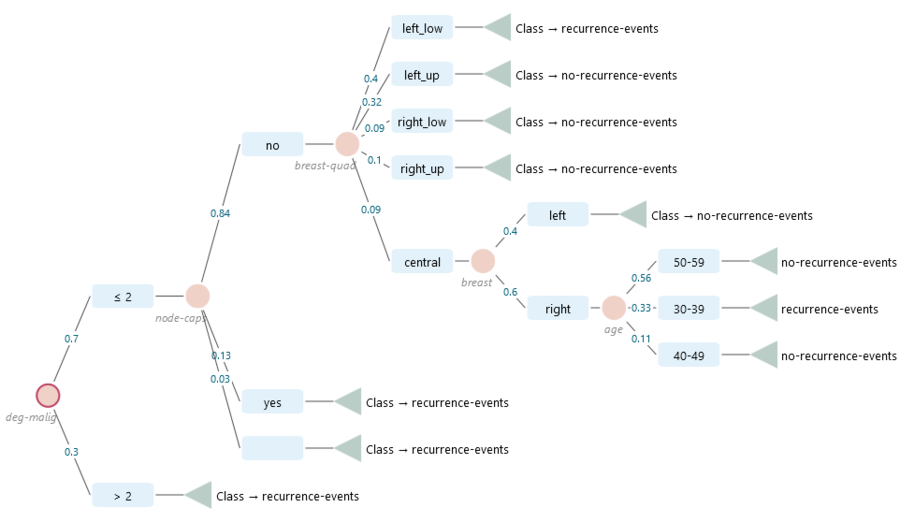
Breast Cancer Data set - example.
Let's do something real and useful. We can analyze the breast cancer data set and get a decision tree on the recurrence event classification.
You can get the CSV file dataset from this link: https://datahub.io/machine-learning/breast-cancer
The Dataset looks like this:
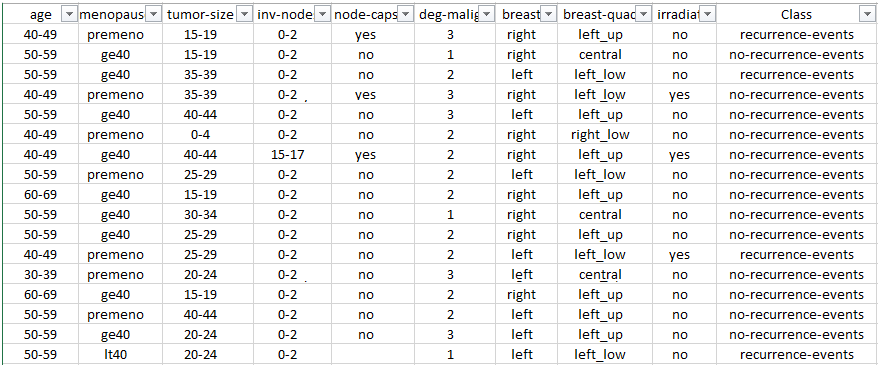
Now, start the Decision Tree software and open the Machine Learning wizard the same as shown in the previous section. Choose the CSV file data source and select the columns as shown below. (Notice that, I have unchecked 2 columns just to create a smaller decision tree).
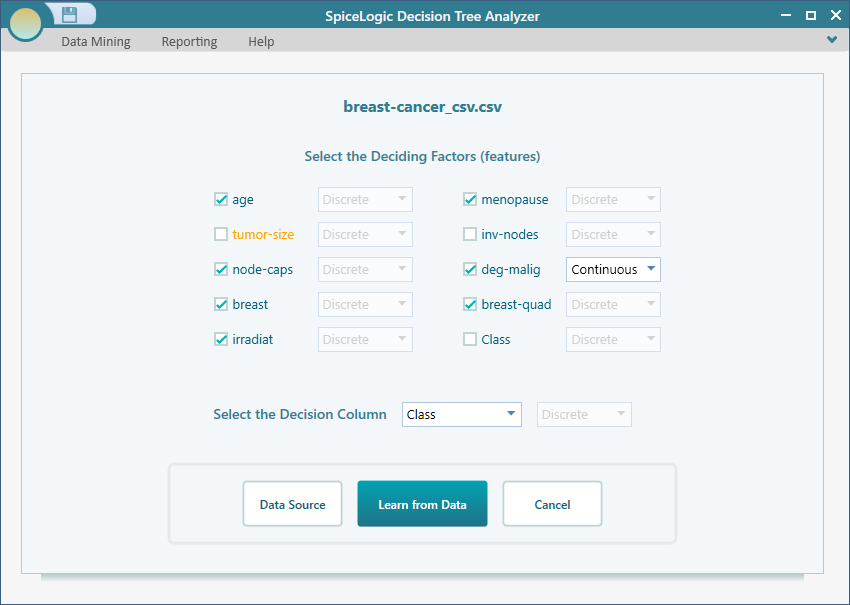
Then click the button 'Learn from Data'. The Decision Tree software will generate a Decision Tree applying machine learning algorithms and produce the decision tree like this.